|
Meng Fang
I am an Assistant Professor in AI at University of Liverpool. I'm also a visiting (assistant) professor at Eindhoven University of Technology (TU/e).
I co-lead the UTS NLP Group.
I had been a research scientist/intern at Tencent Robotics X / AI, CSIRO and Microsoft Research Asia before.
People / Teaching & Service / Email / Github / Scholar / |

|
Updates
|
| Research |
|
Projects |
|

|
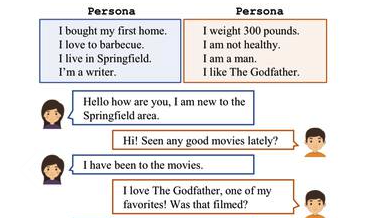
Text-based games |
|
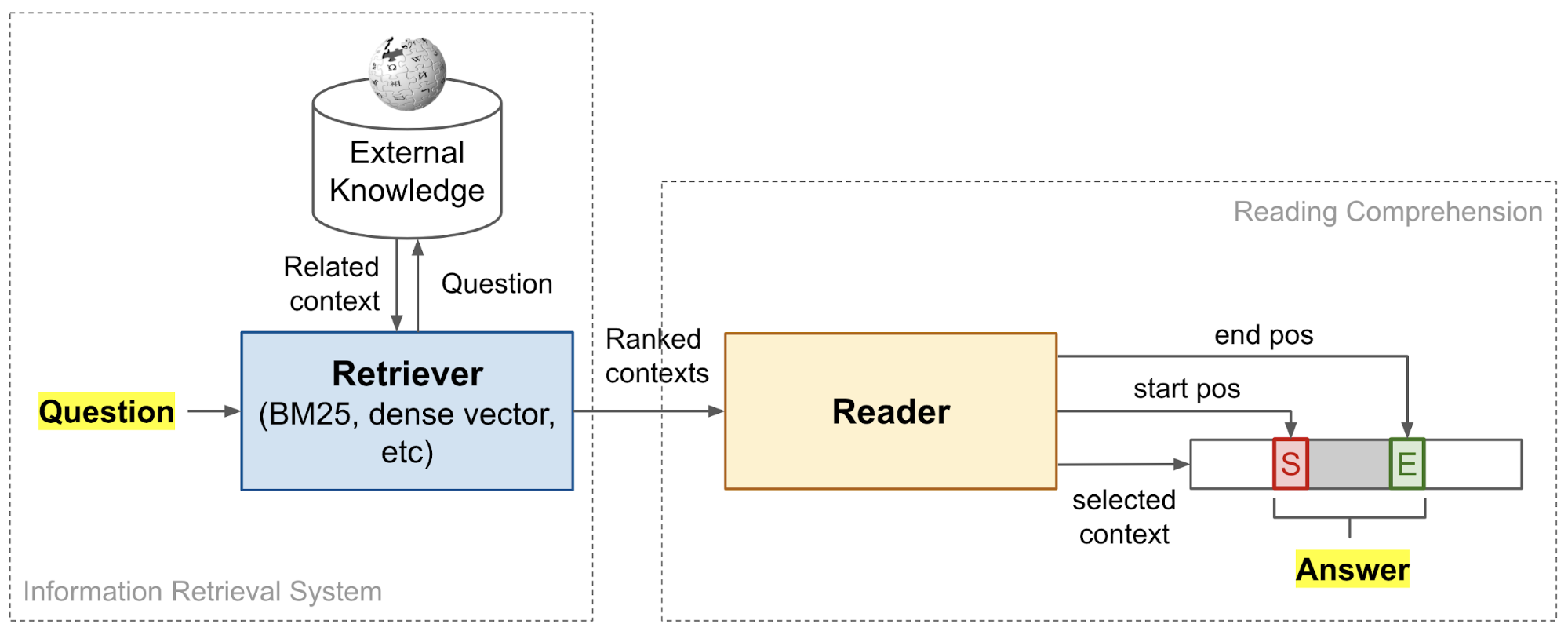
Conversational AI |
|
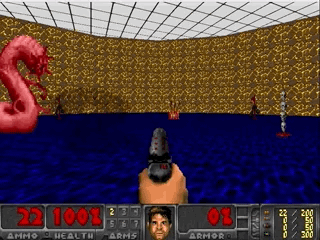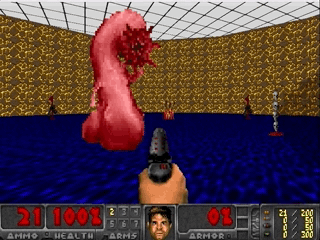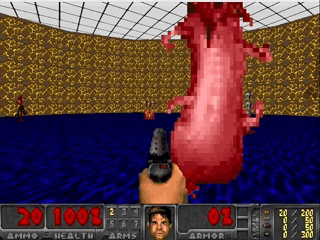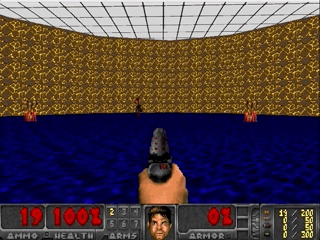
Question & Answering |

|
Reinforcement learning |
|
Publications |
|
|
Selected: (Full publication list) |
|
|
Where Would I Go Next? Large Language Models as Human Mobility Predictors |
|
|
Human-Guided Moral Decision Making in Text-based Games |
|
|
Large Language Models Are Neurosymbolic Reasoners |
|
|
CHBias: Bias Evaluation and Mitigation of Chinese Conversational Language Models |
|
|
NLG Evaluation Metrics Beyond Correlation Analysis: An Empirical Metric Preference Checklist |
|
|
A Survey for Efficient Open Domain Question Answering |
|
|
Stay Moral and Explore: Learn to Behave Morally in Text-based Games |
|
|
Interpretable Reward Redistribution in Reinforcement Learning: A Causal Approach |
|
|
COOM: A Game Benchmark for Continual Reinforcement Learning |
|
|
Perceiving the World: Question-guided Reinforcement Learning for Text-based Games |
|
|
Fire Burns, Sword Cuts: Commonsense Inductive Bias for Exploration in Text-based Games |
|
|
A Model-agnostic Data Manipulation Method for Persona-based Dialogue Generation |
|
|
Rethinking Goal-Conditioned Supervised Learning and Its Connection to Offline RL |
|
|
TASA: Deceiving Question Answering Models by Twin Answer Sentences Attack |
|
|
Is Neural Topic Modelling Better than Clustering? An Empirical Study on Clustering with Contextual Embeddings for Topics |
|
|
Phrase-level Textual Adversarial Attack with Label Preservation |
|
|
Generalization in Text-based Games via Hierarchical Reinforcement Learning |
|
|
DAGN: Discourse-Aware Graph Network for Logical Reasoning |
|
|
Deep Reinforcement Learning with Stacked Hierarchical Attention for Text-based Games |
|
|
Curriculum-guided hindsight experience replay |
|
|
DHER: Hindsight experience replay for dynamic goals |
|
|
Bag: Bi-directional attention entity graph convolutional network for multi-hop reasoning question answering |
|
|
Learning how to Active Learn: A Deep Reinforcement Learning Approach |
|
|
Model transfer for tagging low-resource languages using a bilingual dictionary |
|
|
Networked bandits with disjoint linear payoffs |
|
| Awards |
| Acknowledgements I would like to thank all my collaborators, interns and students. |
|
|